韓国がスーパーコンピュータ6号機(スパコン6号機)の導入準備を本格化することが分かった。2023年の導入を目標に進める。前回よりも導入スピードが速まっており、スパコン世界一となった日本の富岳と性能差が広がっていることや、それに対する批判に対応した可能性がある。
韓国の専門紙etnewsは7日、韓国科学技術情報研究院(KISTI)がスパコン6号機導入への準備を加速するとし、今年の夏までにスパコン6号機の需要調査と意見収集公聴会などを行い、遅くとも11月にはスパコン6号機導入の最終報告書を出すと報じた。
同紙によると、KISTIのスパコン6号機は、1秒に100京回の演算(1exa Flops)が可能なエクサスケール、または少し劣るプレエクサスケールスパコンを念頭に置いているとされる。現在運用中のスパコン5号機(ヌリオン)は1秒に2京5700兆回の演算が可能だ。
Etnewsによると、KISTIは加速器を大幅活用、相対的に狭い物理空間を活用しつつも性能は飛躍的に高める「ヘテロコンピューティング」方法論の適用も考えているという。これらにより大規模な計算およびデータ基盤の研究を進められるようにするという事前構想だ。
ヌリオンは2018年に稼働したが、これは4号機以来10年振りのことだった。今回(6号機)はそのタイムラグを大幅に縮小しようとしており、スパコンのアップデートに対するKISTI側の真剣度が伺える。KISTIは、政府との協議を必要とされる予備妥当性調査の免除などを要請することで、導入までの時間を早めたい考えのようだ。
日本の富岳がスパコン世界1位に浮上するなか、韓国のスパコンは逆にランクを下げていた(17位→21位)ことから、韓国メディアでは「スパコン完敗」に対し政府批判などが噴出していた。
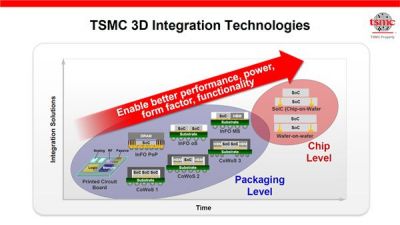
https://korea-elec.jp/posts/21040804/NVIDIAの巨大GPUを支えるTSMCのインタポーザ技術
第2世代のCoWoS2は、NVIDIA GPUなどの大型で高性能なチップやHBM2などの新メモリに最適化した技術となっている。
https://pc.watch.impress.co.jp/docs/column/kaigai/1064109.html
TSMCはパッケージとして売っていてHBM2を単独で販売してないだけじゃないの?>>445
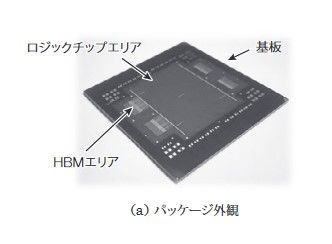
画像を一つ忘れたTSMCのパッケージというのは富岳だけのものではなく「普段から」やっていること
NVIDIAもTSMCのパッケージ技術を使っている
なのでHBM2を作れないとしたらSKやサムスンから大量に購入していることになる
そんな事するか?
わざわざライバル会社から買うより自分で作ったほうがいいだろ
技術だって当然あるはず
使っている機械や素材はサムスンと同様の日本製などの海外製でしょうし>>448
それに一般民生機クラスのメモリを富岳やNVIDIAのハイエンド製品に組み込むのか。
自社でクオリティの高いメモリが作れるならそれを使うのが当然のこと。
そもそも、韓国メディアが業界の関係者や推測で言ってるだけでNVIDIAも富士通もTSMCもメモリをTSMC以外で調達しているっていってないしな。家電メーカーが部品を他社から買うのはよくあるがTSMCは半導体が「本業」だからな。
それを他社から買うとか不自然なこと。
これを見るとメモリやGPUを「一体化」したのをパッケージと言うのだろうな
買ってきた部品を並べるだけなら特別な技術ではないでしょ
https://www.fujitsu.com/jp/documents/about/resources/publications/magazine/backnumber/vol68-1/paper04.pdf
2019/12/21 — 中国蘇州で開催されたGTC 2019で、NVIDIAのCEOは、報道によると、次世代7nm GPUの大部分の注文はTSMCによって処理され、サムスンは以前に報告されたよりも小さな役割しか果たさないと答えました。
https://g-pc.info/archives/13839/
ちょっと前の記事だけどおまけまだやったるの、、、
そっか、丸一日空いていたんだな
昨日は体調が悪くて仕事だけで精一杯だったそもそもサムスンに技術力があるならTSMCではなくサムスンに製作を依頼すればいい。
サムスンも積極的にファウンドリー事業を展開してるしな。
TSMCを選択したのはCPUやCoWoSとInFOといった技術があり、メモリを含めた製作ができるからだろ。>>443
いやいや、貴方は自身の偏見に囚われてる。見たい情報に飛びつく朝鮮人と同じ行動になってるぞ。
TSMC はメモリー半導体は作らんよ。ビジネスとして合理性がないから。
メモリーとディスクリート半導体って、要素技術は同じでも製造法が別物と言えるほど違うし、チップの値段も2桁以上違う。生産量も2桁違う。簡単に組み替えてできるものじゃないし、高い注文が山のようにあるビジネスしてるのに安いチップに組み替えるなんて馬鹿ですか? ってこと。
日本には半導体技術があるのに、半導体生産から撤退してきたのは何故? 理由は結局の所儲からないから。半導体でも特殊な半導体(パワー半導体など)を作ってるのは何故? それで儲かるから。いくら技術があっても儲からないならやらないよ。>>454
そうだよ。
付加価値のある半導体なら日本は製造する。
TSMCも同じ。>>454
初の5nm SRAMがTSMCから、メモリーのアジア優位は揺るがず
https://xtech.nikkei.com/atcl/nxt/event/18/00098/00012/
嘘つくなよ朝鮮人
「朝鮮人と同じ」
最近覚えた言葉か?
そんな事してもバレバレだぞ
じゃあサムスンは儲からないメモリーを作っているということか?
アホだろ日本が半導体の大量生産から撤退した理由。
・価格勝負で負けた
現在の韓国の人件費は日本と変わらないが、サムスンは他の国で安く作っている
中国では中学生が働いているという話もある
日本企業はそんな事はできない
・韓国も台湾も「国運」をかけて莫大な投資をして規模を拡大した
・日本は他に作るものがあるのでそこまで必死になる理由はない
でも現在も一部は作っている>>459
そんな言葉は韓国にしかない>>459
下請けや安物しか作れない韓国w>>462
お前のことか、
バカというのはw>>464
찐타>>464
입닥쳐 이 빨갱이 새끼야>>444
いや、誤解を与えた様で済まない。貴君の主張通りソフトとハードは車の両輪だしで双方が相まって性能を発揮する訳だが、このスレの議論を見ていてハード、特にメモリやプロセスの汲々としていたのであの様な表現をとって締まった、それに付いては謝罪する。
前文でも書いた様に1980年代最強のマシンが富士通のハードにIBMのソフトという組み合わせだった、これは取りも直さず強力なハードウエアとそれを効率的に動かせるフトウエアの合作で、換言すればOSの要求に耐えうる優秀なハードを作れたという事に他ならない。当初米国で「FACOM」というブランド名を「Fuck-On」と揶揄されながらも必死で研究開発に努力して来た当時の技術屋の精神とノウハウが受け継がれ、A64FXや富岳という一つの結実を見た事は素晴らしい事だと思う。
富岳全体を見た場合、私が面白いなと思ったのがCMUの冷却ですね。水冷の場合、巨大なコールドプレートに大量の水を流し全体を一気に冷やすと発想するのですが、ユニット内の冷却を複数のユニットに分けローパワーからハイパワーへと水を流して行く。熱抵抗に依るストレスの軽減にもなるし、ローパワー部である程度暖められた水をハイパワー部に送る事で熱衝撃による吸収率低下の防止にも成る。
全ての面で最高を求める姿勢を貫かないと究極の性能は引き出せない、それには原理に立ち返れる知識とコツコツとノウハウを蓄積する根気と云うか執念が必要です(因みに、トランジスタの発明者のウイリアム・ショックレーは偶然の発見から点接触トランジスタを発表する迄長い試行錯誤を繰り返した、その時の研究ノートの表紙に”tenacity”「執念」と書かれていたそうだ)。
他者の好意や商取引で得た結果を誇ったり、ましてや技術や意匠をパクたり盗んで迄優位に立とうする民族には「究極」は無理でしょうね。>>443
>>454
いやーTSMCはメモリを作っているちゃ作っているんですよ。只メモリ単体では商売してないという事で。
TSMCは随分前からシステムデバイスの中にS-RAMやD-RAMを作り込んでいるので、要求さえ有ればそれらを単体で製造販売するでしょう、但し相当高価になると思いましょ(パワーデバイスも同様)。
そもそもTSMCは1987年に創業された所謂ファンドリー、つまり受託製造専門のメーカで、半導体の世界ではこの種のビジネスモデルの先駆者で、自ら設計や販売は一切行っていない。
そしてもう一つの特徴が最新のテクノロジーから旧テクノロジーまで幅広い製品の製造が可能という事です。これは使用するウエファのサイズで表して居る様ですな、12in・8in・6inの工場が有り、おそらく工場はそのサイズが主流だった頃の装置を使っている(最新の工場が有るのにわざわざ古い規格の工場に最新機器を入れる意味が無い)つまり最新の10nm以下のプロセスを12in工場で、50nm以下を8in、それ以前のプロセスを6in工場(VLSIの生産が始まったのが6in-1980年代)で製造するのでは?。
古いテクノロジーに関し他は、今でもゲルマニュームダイオードやトランジスタを作っているメーカーは有りますし、パチンコ業界では許認可の関係で殆どがディスコンと成った1980年代のデバイスなどを使っていているのでここら辺りの需要も有るんじゃないかな。>>462
朝鮮人は論理ではなく自分の考えと違うやつは馬鹿、自分に従う人は頭がいいだからな。
お前らに批判されるのは光栄だよw>>482
DAEWOOってのもありましたねぇ。
日本ではツクモが扱っていて、、、Kの法則ですかね。
2012年韓国の技術で作ったスーパーコンピューター『チョンドゥン(天動/雷)』がこれですからねぇ
https://news.naver.com/main/read.nhn?mode=LSD&mid=sec&sid1=105&oid=003&aid=0004823993
その後日本のやCRYAとかね。結局1から開発したものはなかったと思いますよ。
韓国未来創造科学部(部は省)は2016年4月4日、今後10年間毎年100億ウォン(約10億円)ずつ、国産スーパーコンピュータ開発に投資する計画を発表した。韓国政府が国を挙げて国産スーパーコンピュータの開発に投資するのは、これが初めてである。
で、今に至るんですが、、、>>481
そうですね、こういう所はIBMというよりアメリカの凄い所で、製品より先に規格を作り公開する。昨今のPCの隆盛もDOS-V(IBM-PC/AT)のATバス規格を公開した事で互換機の製造が可能となった事が切っ掛けですからね、それに比べPC98は閉鎖的98バスも非公開で唯一の互換機がエプソンだった。笑い話に聞こえるけど、NECの技術ですらシステムをいじるのにアスキーだったかが出している「ハンドブック」が無いと出来ないし、スペックがいい加減だから動作異常は無条件で交換(社内ユーザーだからで一般客は門前払い)だっったよ。だから98の年(1998年)に製造終了に追い込まれたんだよね。
本当に寒かった、夏服で徹夜のデバッグなんてしてると朝方指が動かなく成ったりして、CUPのボックスにし。がみついて暖を取ったりしましたね、贅沢っちゃ贅沢ですがねW
確か磁器コアメモリは中国系アメリカ人の発明じゃなかったかな、でも大量の細かいコアを格子状に配列し細い線で編み込む構造は手先の器用な日本人向きで日本に工場を造ったんじゃなかったかな?他にも今のTDKとかが作っていたと聞きます。日本人が発明したのは磁器論理素子じあ無かったかなうろ覚えで申し訳ない。>>484
パソコンというかマイコンの時代ですかなぁ
アキバのビットインにはお世話になりましたねぇ
この当時は非公開ものが多かったですが、意外と直接メーカーに聞くと教えてくれる情報も多かったと思います。
NEC以外にもシャープ、富士通などなどしのぎを削っていた時代なんで、自社のPCで色々やってくれるマニアというかオタクには優しかったです。
確かに、長い時間いると寒くなりましたね。当時はパンチカードとかさんこうテープでしたかね。
よくあんなもんでプログラムの入力やってたものだと今になっては思いますがw
パラメトロンとかは日本人ではなかったですか、FACOMでも採用してたと思いますが。>>486
パラメトロン式計算機
東京大学ではパラメトロンを用いた電子計算機PC-1を1958年に試作した.パラメトロンは東京大学理学部高橋秀俊研究室の後藤英一により発明された.PC-1は,命令語は18ビットの短語,数値は短語18ビット,長語36ビットの固定小数点2進法計算機であった.命令体系はEDSACに似ているが一部変更されている.PC-1の記憶装置には512短語の2周波方式磁心記憶が用いられた.演算時間は加減算が0.4ms,2進36桁の乗算が4.4ms,除算は16.1msであった.また,入出力プログラムには,和田英一(東京大学)が,EDSACのイニシャルオーダを参考に,命令語数を少なくするための工夫を盛り込んで作ったイニシャルオーダが使用された.当時東京大学理学部で利用できる唯一の電子計算機であったため種々の科学計算やプログラム手法の研究に使用された.現在PC-1の現物は存在しないが,和田英一によりノートPC上でPC-1シミュレータが実現され,当時のプログラムが動作している
https://museum.ipsj.or.jp/computer/dawn/0016.html
写真はFACOM201パラメトロン電子計算機(1960年、東京理科大学近代科学資料館所蔵)#大好きだよ安倍晋三
ついで
CPUに参入 米 エヌビディア YouTubehttps://www.youtube.com/watch?v=deOUW9qqFXM
YouTubehttps://www.youtube.com/watch?v=deOUW9qqFXM
どこが作るのかな?>>490
NVIDIA、ArmベースのCPU「Grace」を発表
NVIDIAは2021年4月12日(米国時間)、データセンター向けCPU「Grace」を発表し、CPU市場に正式に参入した。同CPUは、大規模なAI(人工知能)やHPC(ハイパフォーマンスコンピューティング)市場向けに、GPUと組み合わせる設計となっている。
GPUは、高いメモリ帯域幅を持つ高速な計算のために設計されているが、メモリとGPUの間にあるCPUが、データをGPUに送信する際に、しばしばボトルネックになるとHuang氏は説明する。同氏は、GPUのメモリに収まりきらないほど巨大なAIモデルを想定したトレーニングシステムについて説明した。「典型的なシステムでは、4つのGPUと、それぞれ2Tバイト/秒で動作する、合計80Gバイトの超高速メモリが搭載されていることが多い。GPUの横には、わずか0.2Tバイト/秒で動作する1Tバイトのメモリを搭載したCPUがある。CPUのメモリはGPUの3倍の大きさだが、速度は40倍も遅いのだ」(Huang氏)
CPUと各GPU間において、より高速なメモリと専用の通信チャンネルがあれば、こうした状況は改善するが、PCIe(PCI Express)がボトルネックとなる。GPU間の通信向けに設計された「NVLink」を用いる方法もあるが、NVLinkをサポートするx86ベースのCPUはない。
米国のコンピュータプログラミングの先駆者であるGrace Hopper氏にちなんで名付けられたNVIDIAのGraceは、NVLinkを4チャンネル備え、NVIDIAのGPU間との間で900Gバイト/秒の双方向通信を達成したとする。
Graceでは、LPDDR5を採用。LPDDR5は、DDR4に比べて2倍の帯域幅と、10倍のエネルギー効率を実現する。LPDDR5はモバイルの世界では既に普及しているが、NVIDIAは、パートナー各社との協力を通じて、ECC(誤り訂正符号)や冗長性といったメカニズムによって、サーバでも採用できるような信頼性を実現したとする。
https://eetimes.jp/ee/articles/2104/13/news103.html
韓国が次期スパコンを早期導入か…「富岳に完敗」で批判噴出 1秒100京回演算機を検討
492
ツイートLINEお気に入り 428
428 60
60









レス投稿
画像をタップで並べ替え / 『×』で選択解除